The Power of Points for Modeling Humans in Clothing

Abstract
Currently it requires an artist to create 3D human avatars with realistic clothing that can move naturally. Despite progress on 3D scanning and modeling of human bodies, there is still no technology that can easily turn a static scan into an animatable avatar. Automating the creation of such avatars would enable many applications in games, social networking, animation, and AR/VR to name a few. The key problem is one of representation. Standard 3D meshes are widely used in modeling the minimally-clothed body but do not readily capture the complex topology of clothing. Recent interest has shifted to implicit surface models for this task but they are computationally heavy and lack compatibility with existing 3D tools. What is needed is a 3D representation that can capture varied topology at high resolution and that can be learned from data. We argue that this representation has been with us all along — the point cloud. Point clouds have properties of both implicit and explicit representations that we exploit to model 3D garment geometry on a human body. We train a neural network with a novel local clothing geometric feature to represent the shape of different outfits. The network is trained from 3D point clouds of many types of clothing, on many bodies, in many poses, and learns to model pose-dependent clothing deformations. The geometry feature can be optimized to fit a previously unseen scan of a person in clothing, enabling the scan to be reposed realistically. Our model demonstrates superior quantitative and qualitative results in both multi-outfit modeling and unseen outfit animation. The code is available for research purposes.
TL;DR
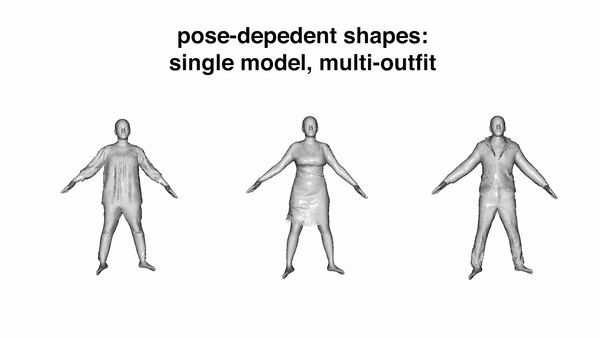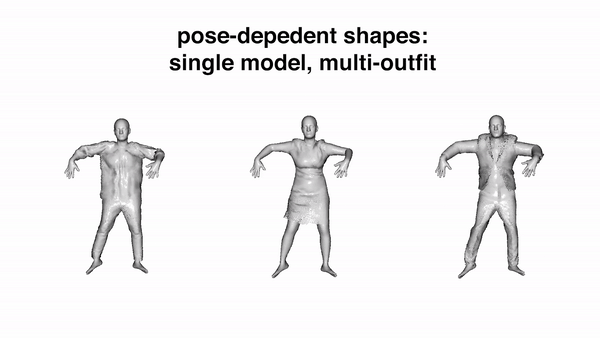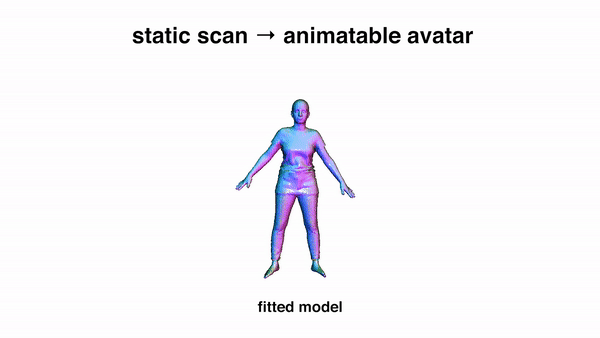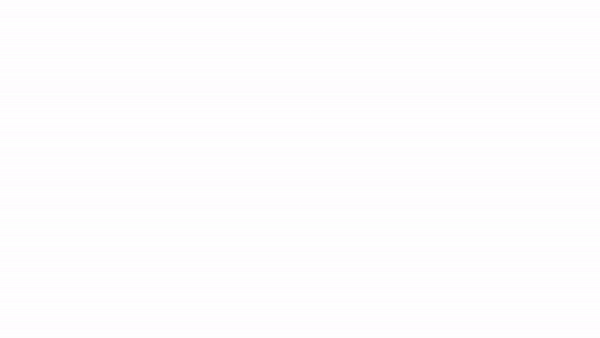
Video
中国大陆的朋友可在B站观看 | The video is also available on Bilibili from mainland China
Paper

The Power of Points for Modeling Humans in Clothing
Qianli Ma, Jinlong Yang, Siyu Tang and Michael J. Black.
In ICCV 2021
[Paper (CVF Version)] [Supp] [arXiv]
@inproceedings{POP:ICCV:2021,
title = {The Power of Points for Modeling Humans in Clothing},
author = {Ma, Qianli and Yang, Jinlong and Tang, Siyu and Black, Michael J.},
booktitle = {Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)},
pages = {10974--10984},
month = October,
year = {2021},
month_numeric = {10}}
Related Projects
SCALE: Modeling Clothed Humans with a Surface Codec of Articulated Local Elements (CVPR 2021)
Qianli Ma, Shunsuke Saito, Jinlong Yang, Siyu Tang, Michael J. Black
Our previous point-based model for humans: modeling pose-dependent shapes of clothed humans explicitly with hundreds of articulated surface elements:
the clothing deforms naturally even in the presence of topological change!
SCANimate: Weakly Supervised Learning of Skinned Clothed Avatar Networks (CVPR 2021)
Shunsuke Saito, Jinlong Yang, Qianli Ma, Michael J. Black
Our implicit solution for articulated shape modeling: cycle-consistent implicit skinning fields + locally pose-aware implicit function =
a fully animatable avatar with implicit surface from raw scans without surface registration!
Learning to Dress 3D People in Generative Clothing (CVPR 2020)
Qianli Ma, Jinlong Yang, Anurag Ranjan, Sergi Pujades, Gerard Pons-Moll, Siyu Tang, Michael J. Black
CAPE — a generative model and a large-scale dataset for 3D clothed human meshes in varied poses and garment types.
We trained POP using the CAPE dataset, check it out!
Acknowledgements
We thanks Studio Lupas for the help with creating the clothing designs used in the project.
We thank Shunsuke Saito for the help with data processing during his internship at MPI.
Q. Ma acknowledges the funding by Deutsche Forschungsgemeinschaft (DFG, German Research Foundation)
and the support from the Max Planck ETH Center for Learning Systems.
The webpage template is adapted from those of
RADAR and
Neural Parts.